Sound source localization (SSL) plays an important role in many signal processing applications, including robot audition, camera surveillance, and source separation. Conventionally, SSL algorithms focus on localizing all active sources in the environment, yet cannot distinguish a target speaker from competing speakers or directional noises.
Recently, researchers from the Institute of Acoustics (IOA) of the Chinese Academy of Sciences addressed the problem of target source localization from a novel perspective by first performing target source separation before localization.
The paper entitled “Target Speaker Localization Based on the Complex Watson Mixture Model and Time-Frequency Selection Neural Network” was published online in Applied Sciences.
Based on the sparsity assumption of the signal spectra, there exist target-dominant time-frequency regions that are sufficient for localization, even if the signal is severely corrupted by noises or interferences.
Hence, the challenge is how to separate the target source from the non-target sources.
Researchers adopted a speaker-aware deep neural network to estimate the target binary masks. Speaker-awareness was achieved by using a short adaptation utterance containing only the target speaker as input to an auxiliary adaption network.
Moreover, the microphone observations were modeled applying a complex Watson mixture model, which made full use of both the inter-channel level difference and phase difference to perform localization.
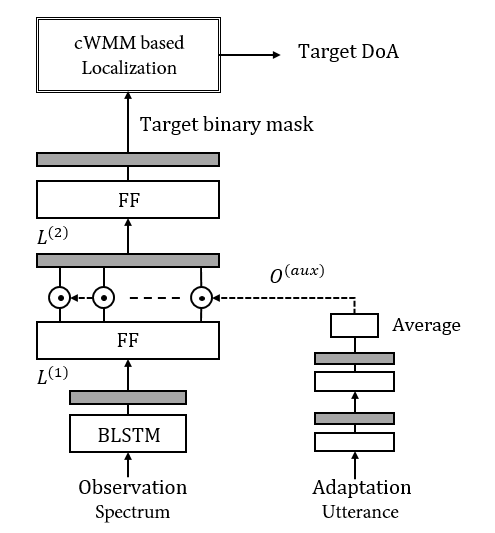
Figure 1. The flowchart of target source mask estimation neural network .(Image by WANG Ziteng)
Simulative experiments showed that the proposed method worked well in various noisy conditions and remained robust when the signal-to-noise ratio was low and when a competing speaker coexisted.
Reference:
WANG Ziteng, LI Junfeng, YAN Yonghong. Target Speaker Localization Based on the Complex Watson Mixture Model and Time-frequency Selection Neural Network. Applied Sciences. 2018, 8(11), 2326; DOI:10.3390/app8112326.
Contact:
WANG Rongquan
Institute of Acoustics, Chinese Academy of Sciences, 100190 Beijing, China
E-mail: media@mail.ioa.ac.cn