

Early speech recognition systems tried to apply a set of grammatical and syntactical rules to speech. If the words spoken fit into a certain set of rules, the program could determine what the words were. However, human language has numerous exceptions to its own rules, even when it's spoken consistently. Accents, dialects and mannerisms can vastly change the way certain words or phrases are spoken. Imagine someone from Boston saying the word "barn." He wouldn't pronounce the "r" at all, and the word comes out rhyming with "John." Or consider the sentence, "I'm going to see the ocean." Most people don't enunciate their words very carefully. The result might come out as "I'm goin' da see tha ocean." They run several of the words together with no noticeable break, such as "I'm goin'" and "the ocean." Rules-based systems were unsuccessful because they couldn't handle these variations. This also explains why earlier systems could not handle continuous speech -- you had to speak each word separately, with a brief pause in between them.
Today's speech recognition systems use powerful and complicated statistical modeling systems. These systems use probability and mathematical functions to determine the most likely outcome. According to John Garofolo, Speech Group Manager at the Information Technology Laboratory of the National Institute of Standards and Technology, the two models that dominate the field today are the Hidden Markov Model and neural networks. These methods involve complex mathematical functions, but essentially, they take the information known to the system to figure out the information hidden from it.
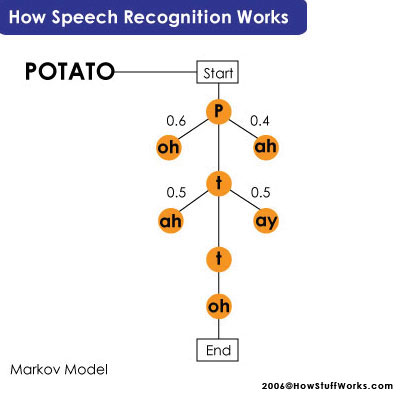
The Hidden Markov Model is the most common, so we'll take a closer look at that process. In this model, each phoneme is like a link in a chain, and the completed chain is a word. However, the chain branches off in different directions as the program attempts to match the digital sound with the phoneme that's most likely to come next. During this process, the program assigns a probability score to each phoneme, based on its built-in dictionary and user training.
This process is even more complicated for phrases and sentences -- the system has to figure out where each word stops and starts. The classic example is the phrase "recognize speech," which sounds a lot like "wreck a nice beach" when you say it very quickly. The program has to analyze the phonemes using the phrase that came before it in order to get it right. Here's a breakdown of the two phrases:
r eh k ao g n ay z s p iy ch
"recognize speech"
r eh k ay n ay s b iy ch
"wreck a nice beach"
Why is this so complicated? If a program has a vocabulary of 60,000 words (common in today's programs), a sequence of three words could be any of 216 trillion possibilities. Obviously, even the most powerful computer can't search through all of them without some help.
That help comes in the form of program training. According to John Garofolo:
These statistical systems need lots of exemplary training data to reach their optimal performance -- sometimes on the order of thousands of hours of human-transcribed speech and hundreds of megabytes of text. These training data are used to create acoustic models of words, word lists, and [...] multi-word probability networks. There is some art into how one selects, compiles and prepares this training data for "digestion" by the system and how the system models are "tuned" to a particular application. These details can make the difference between a well-performing system and a poorly-performing system -- even when using the same basic algorithm.
While the software developers who set up the system's initial vocabulary perform much of this training, the end user must also spend some time training it. In a business setting, the primary users of the program must spend some time (sometimes as little as 10 minutes) speaking into the system to train it on their particular speech patterns. They must also train the system to recognize terms and acronyms particular to the company. Special editions of speech recognition programs for medical or legal offices have terms commonly used in those fields already trained into them.
Next, we'll look at some weaknesses and flaws in speech recognition systems.