

Blind source separation (BSS) aims to estimate source signals from observed mixtures without prior information about the source or mixing system. Audio source separation is originally developed to solve the “cocktail party problem”, and has important applications in the automatic speech recognition, music transcription, and automatic meeting transcription, etc.
In the case of long reverberation times, the full-rank SCM has been introduced by forcing the SCM to be full rank in the full-rank covariance matrix analysis (FCA), multichannel nonnegative matrix factorization (MNMF) and Fast MNMF, which shows improved separation performances. However, the full-rank SCM is still short of physical meaning.
Recently, researchers from the Institute of Acoustics of the Chinese Academy of Sciences (IACAS) proposed a BSS framework based on the frequency-domain convolution transfer function. Without employing the narrowband assumption, they approximated the time-domain convolutive mixture using a frequency-wise convolutive mixture, and proposed a CTF-based MNMF framework for BSS in highly reverberant environments. The full-rank SCM can be derived based on the proposed CTF framework and slowly time-variant source variances, which clearly explains why the full-rank spatial model works well in practice. Based on the CTF framework, the researchers proposed a CTF-based MNMF algorithm for overdetermined BSS.
Experiments show that the proposed algorithm achieves a higher separation performance than the sate-of-the-art ILRMA and Fast MNMF in reverberant environments.
This research provides a new idea for solving the BSS problem in highly reverberant environments.
The research, published online in IEEE/ACM Transactions on Audio, Speech, and Language Processing in January 2022, was supported by National Natural Science Foundation of China (No. 62171438), Youth Innovation Promotion Association of Chinese Academy of Sciences (No. 2018027), and IACAS “Frontier Exploration” Project (No. QYTS202111).
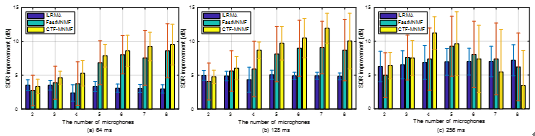
Figure 1: Average SDR improvements in two-source case where Rt60=470 ms. The STFT window length is (a) 64 ms, (b) 128 ms and (c) 256 ms. (Image by IACAS)
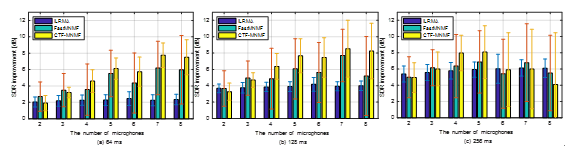
Figure 2: Average SDR improvements in two-source case where Rt60=1300 ms. The STFT window length is (a) 64 ms, (b) 128 ms and (c) 256 ms. (Image by IACAS)
Reference:
WANG Taihui, YANG Feiran, YANG Jun, Convolutive transfer function-based multichannel nonnegative matrix factorization for overdetermined blind source separation, IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 30, pp. 802–815, Jan. 2022. DOI:10.1109/TASLP.2022.3145304.
Contact:
ZHOU Wenjia
Institute of Acoustics, Chinese Academy of Sciences, 100190 Beijing, China
E-mail: media@mail.ioa.ac.cn