

Environmental sound contains a large amount of surrounding information. Compared with speech and music, it has richer contents, thus gradually capturing attention from researchers at home and abroad. Acoustic scene modeling aims to recognize the place where the sound was recorded, which enables devices and robots to be context-aware.
Traditional acoustic features are based on the short-time Fourier transform, such as Mel-frequency cepstral coefficients. However, environmental information is usually stored at different time scales. Accordingly, sensing signal in a multi-scale way is crucial to the task of acoustic scene modeling.
To accomplish the task, recently, researchers from the Institute of Acoustics (IOA) of the Chinese Academy of Sciences proposed a novel framework based on the wavelet transform and deep convolutional neural network. The study was published in Proceedings of the Annual Conference of the International Speech Communication Association (September 2018).
The proposed framework mainly includes two modules, a front-end module based on the wavelet transform and a back-end module based on deep convolutional neural network. The scalogram is the visual representation of coefficients extracted by wavelet filters, which can capture both transient and rhyme information. The back-end network applies small kernels and pooling operations to extract high-level semantic.
Experiments on the acoustic scene dataset demonstrated that multi-scale feature led to an obvious accuracy increase via using the proposed framework, when compared with the short-term features. In addition, the scalogram has a lower time resolution, which saves storage space and reduces computational cost to some extent.
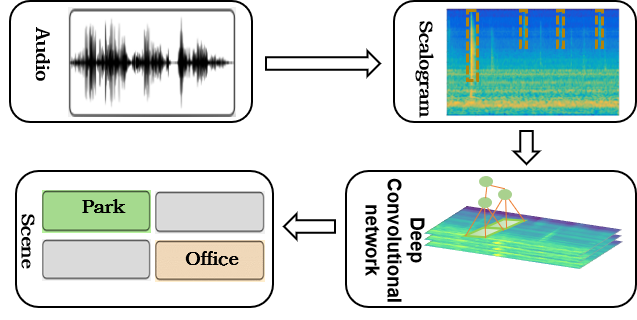
Figure 1. The audio scene framework based on the wavelet transform and deep convolutional neural network (Image by CHEN Hangting)
Reference:
CHEN Hangting, ZHANG Pengyuan, BAI Haichuan, YUAN Qingsheng, BAO Xiuguo, YAN Yonghong. Deep Convolutional Neural Network with Scalogram for Audio Scene Modeling. Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH, v 2018-September, p 3304-3308. DOI: 10.21437/Interspeech.2018-1524.
Contact:
WANG Rongquan
Institute of Acoustics, Chinese Academy of Sciences, 100190 Beijing, China
E-mail: media@mail.ioa.ac.cn