

Speech dereverberation is important for hands-free speech communication systems and human-machine speech interfaces. In reverberant environments, speech quality and speech intelligibility may degrade dramatically due to acoustic reverberation. In addition, speech recognition often fails in highly reverberant conditions. How to effectively suppress late reverberation noise becomes a difficult and hot topic in recent years.
Conventional single-channel speech dereverberation methods, including In order to estimate the late reverberant spectral variance, usually blindly estimate some room acoustic parameters, such as the reverberation time (T60) or the damping constant.
By comparing a speech spectrogram into an image, researcher ZHENG Chengshi and his colleagues from the Institute of Acoustics (IOA) of the Chinese Academy of Sciences proposed a novel single channel speech dereverberation method using guided spectrogram filtering , which can significantly improve speech quality with less computational cost and requires neither room acoustic parameter estimation nor late reverberant spectral variance estimation.
The paper entitled “Guided Spectrogram Filtering for Speech Dereverberation” was published in Applied Acoustics.
Acoustic reverberation has impact on clean speech spectrograms. Considering a clean speech spectrogram as a clean image, its corresponding reverberant version is a corrupted image covered by mist (Figure 1). Based on this fact, researchers proposed a guided spectrogram filtering method to reduce acoustic reverberation.
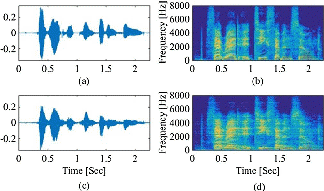
Figure 1. Waveforms and normalized spectrograms of the clean speech (a), (b), the reverberant speech with T60 = 400 ms (c), (d).(Image by IACAS)
In the proposed guided spectrogram filtering (GSF) method, there is no need to estimate the late reverberant spectral variance to suppress the late reverberant speech component. As a result, neither the late reverberant spectral variance estimation nor room acoustic parameter estimation is necessary to implement the proposed method
Objective comparison results, as shown in Figure 2, indicate that the proposed GSF method is economy in single-channel speech dereverberation compared with conventional methods.
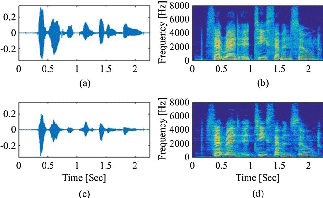
Figure 2. Waveforms and normalized spectrograms of the clean speech (a), (b), the reverberant speech with T60 = 400 ms enhanced by the proposed guided spectrogram filtering method (c), (d).(Image by IACAS)
Reference:
ZHENG Chengshi, TAN Zhenghua, PENG Renhua, LI Xiaodong. Guided Spectrogram Filtering for Speech Dereverberation. Applied Acoustics (Volume 134, May 2018, Pages 154-159). DOI: 10.1016/j.apacoust.2017.11.016.
Contact:
WANG Rongquan
Institute of Acoustics, Chinese Academy of Sciences, 100190 Beijing, China
E-mail: wangrongquan@mail.ioa.ac.cn