

Single speech source localization is of great significance to speech signal processing such as speaker tracking. Single source localization generally requires high computational efficiency and acoustic robustness in reality.
Recently, researchers from the Key Laboratory of Speech Acoustics and Content Understanding of the Chinese Academy of Sciences propose a method based on phase difference regression proves robust for localization of single sound source.
The direction of arrival (DOA) of sound source can be straightforwardly represented as the inverse triangular function of the time delays for linear arrays. The bin-wise time delay regression methods can estimate DOA with high time resolution. For linear arrays, the time delay is denoted as the slope of the scatter figure that is plotted by the phase difference and angular frequency. Both the acoustic robustness and computational efficiency are considered in conventional regression methods.
However, conventional regression methods do not work on planar arrays since the DOA can no longer be represented as the inverse triangular function of delays. Besides, the period of phase difference is often ignored in the regression cost function. This point is seldom mentioned in most regression based methods. Moreover, the weighting method ignores the low-SNR speech components, which maybe still helpful to DOA estimation.
Researchers from the Key Laboratory of Speech Acoustics and Content Understanding of the Chinese Academy of Sciences propose a regression-based method for a planar array, where the cost function is taken as the weighted square error between the straightforward phase difference and the DOA-derived phase difference over all microphone pairs. The proposed method based on phase difference regression proves robust for localization of single sound source.
By solving the first-order derivative of the cost function with respect to zero, DOA is represented as a linear function of all bin-wise delays and the array topology. Both the spatial aliasing and the range of phase difference error are considered in the proposed method. Moreover, the signal enhancement and weighting factor are introduced to mitigate the effect of the acoustic interference.
In order to control the reverberation time, the room with size 7.4 × 3.4 × 2.6 meters is simulated by using an image model. The continuous speech taken from the TIMIT database is used to as the source signal. The reverberation time, T60, is respectively set as 200, 400, and 600ms. The noise, which is recorded on the side of a road with heavy-traffic by using our array, is artificially added to the simulated signal at SNR of 0, 5, 10 dB. The experimental results in Fig.1 confirm that the proposed algorithm consistently achieves better performance under all test conditions.
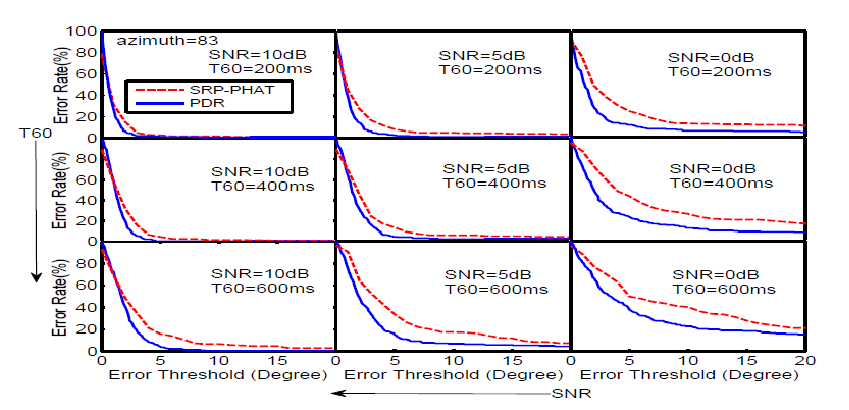
Fig.1 Error rate versus error threshold under various simulated environments (Image by HUANG)
Funding for this research came from the National Program on Key Basic Research Project (2013CB329302), the National Natural Science Foundation of China (Nos. 61271426, 11461141004, 91120001), the Strategic Priority Research Program of the Chinese Academy of Sciences (Grant Nos. XDA06030100, XDA06030500), and the CAS Priority Deployment Project (KGZD-EW-103-2).
Reference:
HUANG Zhaoqiong, ZHAN Ge, YANG Dongwen, and YAN Yonghong. Robust Localization of Single Sound Source Based on Phase Difference Regression. INTERSPEECH 2015, September 6-10, Dresden, Germany.
Contact:
HUANG Zhaoqiong
Key Laboratory of Speech Acoustics and Content Understanding, Institute of Acoustics, Chinese Academy of Sciences, 100190 Beijing, China