

Key words: Phase Change Memory Systems, Performance, Energy Efficiency
Phase change memory (PCM) is a promising technology for future memory thanks to its better scalability and lower leakage power than DRAM (dynamic random-access memory). However, adopting PCM as main memory needs to overcome its write issues, such as long write latency and high write power.
In the conventional memory system, memory requests are firstly buffered in the transaction queue of the memory controller, and then converted to commands to access memory chips. Actually, the transaction queue is a buffer to buffer the addresses and data of memory requests.
The buffer space can be better utilized to reduce memory accesses to PCM. As a result, a victim cache technique that reorganizes the buffer into a victim cache structure (RBC) is proposed. Dirty data from LLC (last level cache) must be written back to PCM memory in the conventional buffer structure, while they can be cached in the victim cache until they are evicted. Compared with the buffer, victim cache can provide additional hits for the last level cache. And thus, RBC can reduce memory accesses, and improve performance and reduce the energy consumption of PCM memory systems.
A PCM rank consisting of multiple memory chips can only support one write command once due to the high write power of PCM and the maximum power constraint. The conventional coarse-grained memory request that involves multiple memory chips limits the write parallelism of chips. Therefore, fined-grained memory accessing that each request which only accesses one PCM chip is adopted in this research.
Since the capacity of victim cache is limited, evicting one cache line once under traditional LRU policy results in frequent eviction. As a result, the performance of PCM memory system is degraded. A chip parallelism-aware replacement policy (CPAR) is further proposed for the victim cache. In addition to the LRU cache line, CPAR evicts multiple cache lines that access different PCM chips. Evicting multiple cache lines can reduce frequent eviction of victim cache. Moreover, evicting caches lines that map different chips can improve write parallelism of PCM chips.
Fig. 1 shows RBC can improve PCM memory system performance by up to 9.4% and 5.4% on average. Combing CPAR with RBC (RBC+CPAR) can improve performance by up to 19.0% and 12.1% on average. In addition to performance, RBC and RBC+CPAR can also reduce read latency and memory energy efficiently.
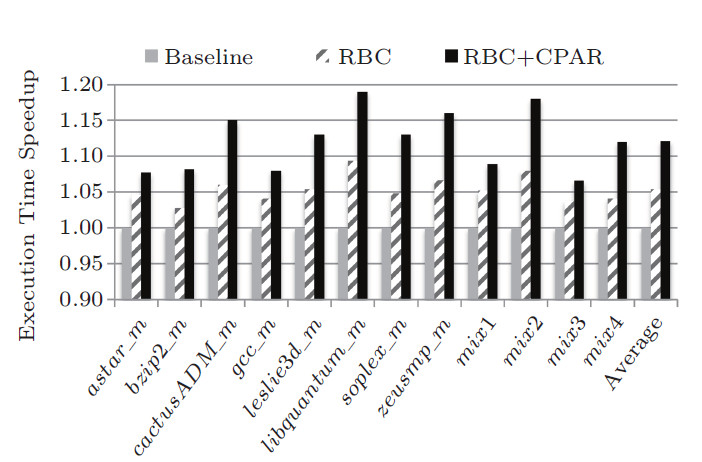
Fig. 1 Execution time speedup (Image by WANG)
References:
WANG Qi, LI Jiarui, WANG Donghui. Improving the Performance and Energy Efficiency of Phase Change Memory Systems. Journal of Computer Science and Technology (vol. 30, no. 1, pp. 110-120, January 2015). DOI: 10.1007/s11390-015-1508-3
Contact:
WANG Qi
Institute of Acoustics, Chinese Academy of Sciences, 100190 Beijing, China
Email: qi0104@126.com