

Keyword: Automatic speech recognition, Pronunciation models, Discriminative training
Current large vocabulary continuous speech recognition (LVCSR) technology aims at transferring real-world speech to sentence. However, due to data scarcity, it is almost impossible to find a sufficiently direct conversion between speech and sentence and the conversion is divided into three parts (Fig. 1). They are speech feature vectors and sub-words (phones for example) described by Acoustic Models (AMs), words and sentence described by Language Model (LM), and sub-words and words described by a lexicon.

Fig.1 The conversions between speech and sentence (Image by SONG)
As well, a lexicon is composed of three parts: words, pronunciations, and Pronunciation Models (PMs) which contain the pronunciation probabilities of each word in the lexicon. To automatically learn a lexicon, earlier research has explored the data-driven pronunciation learning and PM training methods.
As to PM training, researchers from the Institute of Acoustics of the Chinese Academy of Sciences have modified the auxiliary function of the standard Minimum Phone Error (MPE) training to incorporate PMs. And a discriminative pronunciation modeling method using MPE criterion is proposed, called MPEPM. The acoustic models and pronunciation models are co-trained in an iterative fashion under the MPE training framework.
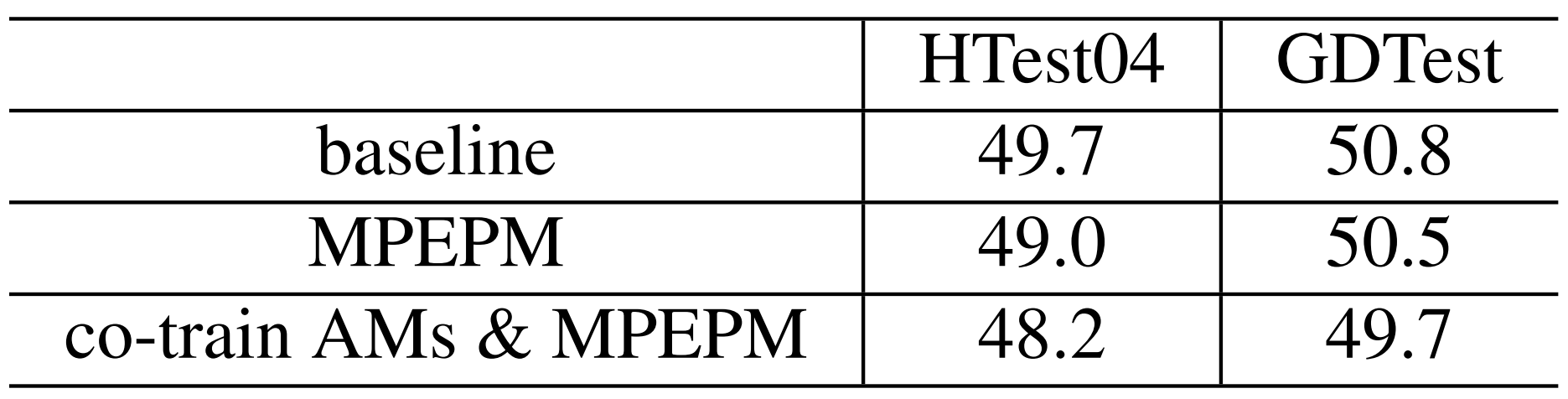
Experiments verified the proposal. In the experiment on Mandarin conversational telephone speech recognition task, there were two test sets. The first was “HTest04” collected by HKUST and released in 2005, and the second was “GDTest” comprised of 354 self-collected conversations by phone.
The character error rate (CER) was used to estimate the recognition performance, which was obtained by a one-pass decoding. The recognition results were shown in Tab. 1. The first row was the result of baseline using a canonical lexicon. And the second rows showed the results of MPEPM without AM co-training. It could be seen that MPEPM alone had obtained 0.7% on HTest04 and 0.3% on GDTest of consistent CER reductions. While the MPEPM was co-training with AM, as the final row showed, 0.8% additional CER decrease could been achieved.
In this innovative method, the required statistics could be obtained in standard MPE training. Thus, this method is easy and efficient to implement. And consistent CER reductions on Mandarin conversational speech recognition task demonstrated the effectiveness of this method.
Tab.1 Results in Character Error Rates (CERs) (%) (Tab by SONG)
References:
SONG Meixu, PAN Jielin, ZHAO Qingwei, YAN Yonghong. Discriminative Pronunciation Modeling Using the MPE Criterion. IEICE TRANSACTIONS on Information and Systems (vol. E98-D, no. 3, Mar. 2015). DOI: 10.1587/transinf.E0.D.1
Contact:
SONG Meixu
Key Laboratory of Speech Acoustics and Content Understanding, Institute of Acoustics, Chinese Academy of Sciences, 100190 Beijing, China
Email: songmeixu@hccl.ioa.ac.cn