

Keywords: language branch variability, discriminative information, factor analysis, language recognition
Language recognition aims to determine the language identity given a segment of speech. With the development of language recognition, it is more concerned about the discrimination between the pairs of languages emphasized in the NIST 2011 Language Recognition Evaluation (LRE). In it, more confusable target languages were evaluated, and new performance metrics which considered only the N worst performance language pairs were defined. This means that all the target languages should be modeled suitably and the discriminative ability between confusable pairs is more important.
Researchers from the Institute of Acoustics, Chinese Academy of Sciences propose language branch variability (LBV) method based on factor analysis. The LBV method aims to strengthen the discrimination between confusable languages. Languages can be divided into different language branches in the perspective of linguistics. Languages in the same language branch share a remarkably similar pattern, and may be related through descent from a common ancestor, or be different dialects in a region.
The proposed method considers the discriminative information of languages from both intra language branch and inter language branches in factor level and model level. In factor level, language branch variability factors are obtained by combing factors mapped on the language branch spaces. And in model level, two groups of SVM models are trained. One group of models covers richer discriminative information of languages of the inner language branched. As well, the other group emphasizes the discrimination between language branches. A block diagram of the process is shown in Fig. 1, taking Arabic Iraqi for example.
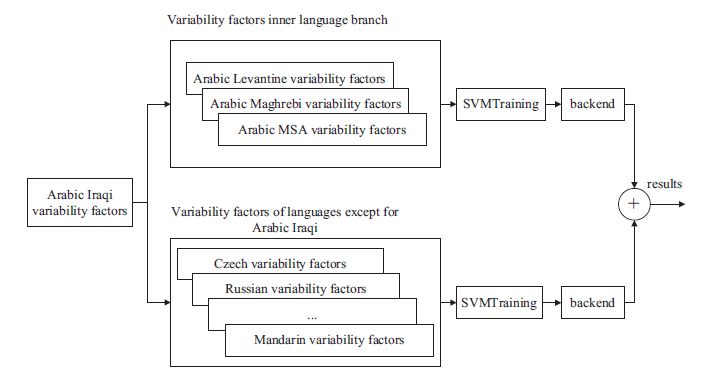
Fig.1 A block diagram for training two groups of SVM models, taking Arabic Iraqi as example (Image by WANG).
Experiments were carried out on the NIST LRE 2011 closed-set task. There were 24 target languages in corpora of 2011 evaluation database. Equal error rate (EER), the minimum decision cost value (minDCF), minimum and actual average cost value (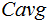 ) in terms of the new
) in terms of the new 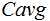 computed on the 24 language-pairs with the highest
computed on the 24 language-pairs with the highest 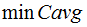 (
(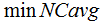 ,
,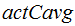 ) and the
) and the 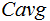 computed for all 276 language-pairs (
computed for all 276 language-pairs (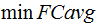 ,
,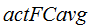 ) are used as metrics for evaluation.
) are used as metrics for evaluation.
Results on 30s task show the LBV method achieves a relatively improvement of 14.6% in EER and 12.9% in minDCF. And it improves by 7.9%, 7.2%, 17.7% and 14.5% on 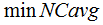 ,
,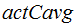 ,
,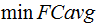 and
and 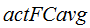 respectively, compared to the total variability system .
respectively, compared to the total variability system .
DET plots are shown in Fig. 2.
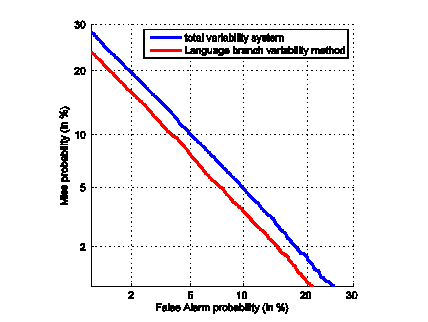
Fig.2 DET curves of systems on NIST 2011 LRE 30s task (Image by WANG).
Fig. 3 gives the performance of the two systems in terms of minDCF, and the 15 language pairs in the same language branch from the 24 worst language pairs are observed.
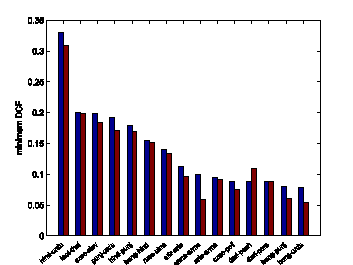
Fig.3 minDCF of the total variability and LBV for 15 language pairs which are in the same language branches from the 24-worst pairs on NIST 2011 LRE 30s task (Image by WANG).
References:
WANG Xianliang, WAN Yulong, YANG Lin, ZHOU Ruohua, YAN Yonghong. Language Recognition System Using Language Branch Discriminative Information. Acoustics, Speech and Signal Processing (ICASSP), 2014 IEEE International Conference on. (pp. 5327-5331, 4-9 May 2014). DOI: 10.1109/ICASSP.2014.6854620
Contact:
WANG Xianliang
Key Laboratory of Speech Acoustics and Content Understanding, Institute of Acoustics, Chinese Academy of Sciences, 100190 Beijing, China
Email: wangxianliang@hccl.ioa.ac.cn