

Acoustic echo often arises in full-duplex speech communication and speech recognition based interactive systems due to the acoustic coupling between the loudspeaker and the microphone. It can deteriorate the quality and reliability of the systems substantially. Therefore, it is essential to eliminate the echo from the microphone signal. Traditionally, acoustic echo canceller is usually exploited to solve this problem. However, the performance is frequently dissatisfactory because of constantly changing echo path and abrupt near-end disturbs in practice.
Researchers from the Institute of Acoustics (IOA), Chinese Academy of Sciences (CAS) present a fast converging method which is insensitive to such changes and disturbances to achieve robust acoustic echo control. Regarding the system identification issue as a multiple linear regression problem, the frequency-domain stage-wise regression model is introduced for acoustic echo control. Moreover, a non-stationarity controlled smoothing (NSCS) factor is proposed alongside the regression procedure to mitigate the increasing variance when no significant echo presents. The signal reconstruction is carried out using overlap-and-add as it is done in ordinary spectral modification framework.
Experiments are carried out to evaluate the performance of the proposed scheme as well as an adaptive controller named Speex. The effect of NSCS is examined first and the result is given by Fig.1. It is obviously observed that the estimation using NSCS generally shows lower variance and does not significantly distort the near-end signal when echo reappears. In the following, the performance in single and double-talk situations is evaluated. The result is depicted in Fig.2. As demonstrated in Fig.2, the proposed method achieves significant higher echo return loss enhancement (ERLE) in the 0 s-3 s and 11 s-13 s and comparable with Speex in the rest part of the time, which confirms the better performance of echo suppression achieved by the proposed algorithm.
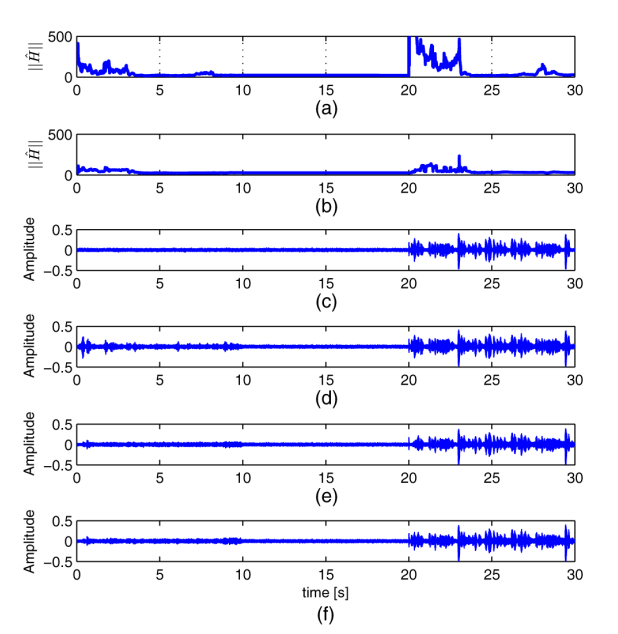
Fig.1. Evaluation of the NSCS.(a) Euclidean norm of the proposed method without NSCS; (b) Euclidean norm of the proposed method with NSCS; (c) pure near-end signal;(d) residual of Speex; (e) residual of proposed method without NSCS ; (f) residual of proposed method with NSCS (Image by IOA).
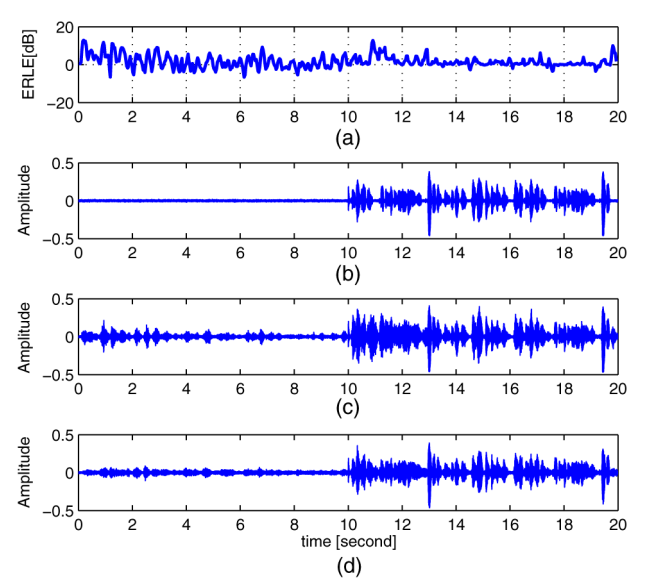
Fig.2. Evaluation under single and double talk. (a) ERLE improvement of the proposed method over Speex; (b) the near-end signal; (c) the estimated near-end signal by Speex; (d) the estimated near-end signal by the proposed method (Image by IOA).
This research is supported by the NSFC under Grant 11161140319, the Strategic Priority Research Program of the CAS under Grants XDA06030100 and XDA06030500, the National 863 Program under Grant 2012AA012503, and by the CAS Priority Deployment Project under Grant KGZD-EW-103-2.
References:
JIANG Kaiyu, WU Chao, GUO Yanmeng, FU Qiang, YAN Yonghong. Acoustic Echo Control with Frequency-domain Stage-wise Regression. Signal Processing Letters, IEEE (Vol. 21, No. 10, pp. 1265-1269, October 2014). DOI: 10.1109/LSP.2014.2331108
Contact:
JIANG Kaiyu, WU Chao
Key Laboratory of Speech Acoustics and Content Understanding, Institute of Acoustics, Chinese Academy of Sciences, Beijing 100190, China
E-mail: jiangkaiyu@hccl.ioa.ac.cn; wuchao@hccl.ioa.ac.cn