

In agglutinative languages, the word can be formed by concatenating suffixes to the stem successively. Theoretically, the number of distinct word types is unlimited in these languages. Due to this agglutinative nature, the word-based automatic speech recognition system with a moderate size vocabulary suffers from the problem of a high out-of-vocabulary rate. To increase the vocabulary’s coverage, sub-words are utilized as the recognition units in the automatic transcription task for agglutinative languages such as Estonian, Hungarian, Finnish, and Turkish. Morphemes, which are obtained from the morphological parsing, and statistical sub-words, which are derived from the data-driven splitting, are two commonly used sub-lexical units.
For a word type, the result of morphological parsing is usually different from that of data-driven splitting. Since there are many differences between the morpheme vocabulary and the statistical sub-word vocabulary, a hybrid vocabulary can be built to take advantage of individual benefits from them.
Complementarity between words and sub-words has been exploited to improve the recognition performance previously. Works focusing on the combination of words and sub-words have been done before, but complementarity of different kinds of sub-words has not been studied.
In this research, a discriminative framework is used to build a hybrid vocabulary with morphemes and statistical sub-words. An objective function which involves the unigram language model probability and the count of misrecognized phones on the acoustic training data is defined and minimized. After the minimization procedure, the optimal splitting result is determined for each word token in the corpus. Frequent morphemes and statistical sub-words are selected from the sub-lexical representation of the corpus to generate the hybrid vocabulary. Compared to a statistical sub-word based system, the hybrid system achieves 0.8% letter error rates reduction on the test set.
This approach is evaluated in the Uyghur conversational telephone speech transcription task. Uyghur is a typical agglutinative language which is similar to Turkish. This method is general and ought to be applicable for other agglutinative languages. Fig.1 shows examples of the tree structure for two Uyghur word types of“kitablirim” and “kitabimning”.
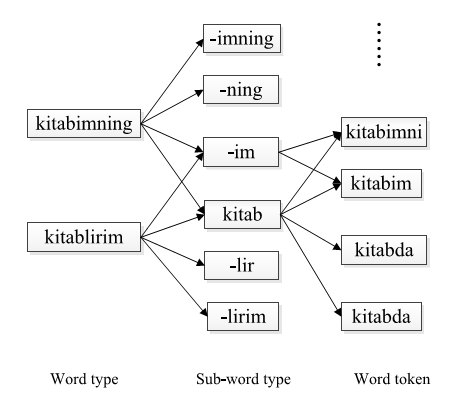
Fig.1 Examples of the tree structure for two Uyghur word types (Image by LI).
This research is partially supported by the National Natural Science Foundation of China (Nos. 10925419, 90920302, 61072124, 11074275, 11161140319, 91120001), the Strategic Priority Research Program of the Chinese Academy of Sciences (Grant Nos. XDA06030100, XDA06030500), the National 863 Program (No. 2012AA012503) and the CAS Priority Deployment Project (No. KGZD-EW-103-2).
The research entitled of "Discriminative Approach to Build Hybrid Vocabulary for Conversational Telephone Speech Recognition of Agglutinative Languages" has been pubulised in IEICE TRANS. INF. & SYST. (Vol.E96–D, No.11, November 2013).
Contact:
LI Xin
Key Laboratory of Speech Acoustics and Content Understanding, Institute of Acoustics, Chinese Academy of Sciences, Beijing 100190, China
E-mail: lixin@hccl.ioa.ac.cn